1.1.1.1 is a public DNS resolver that makes DNS queries faster and more secure.
What is 1.1.1.1?
1.1.1.1 is a public DNS resolver operated by Cloudflare that offers a fast and private way to browse the Internet. Unlike most DNS resolvers, 1.1.1.1 does not sell user data to advertisers. In addition, 1.1.1.1 has been measured to be the fastest DNS resolver available.
What is DNS?
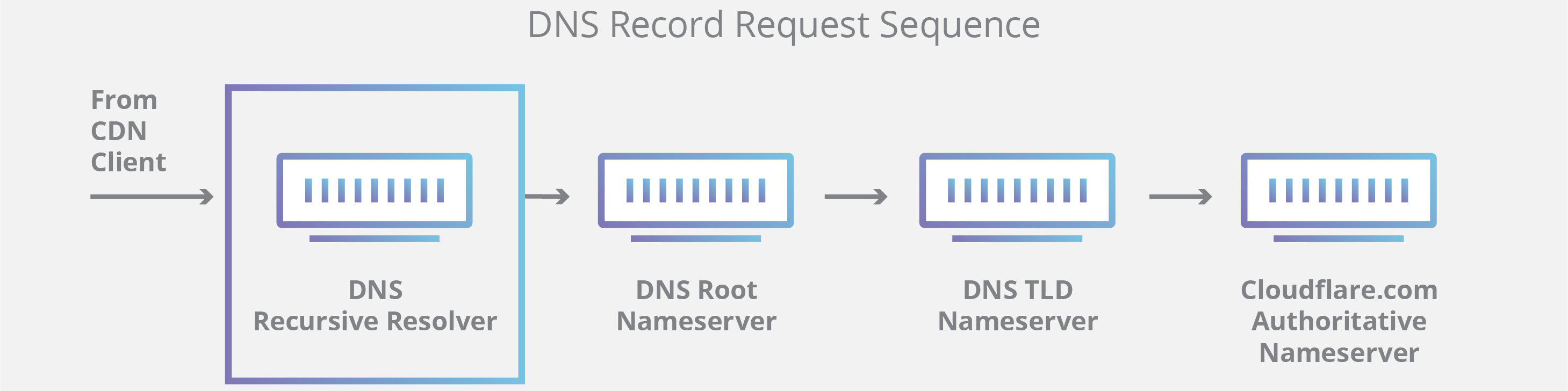
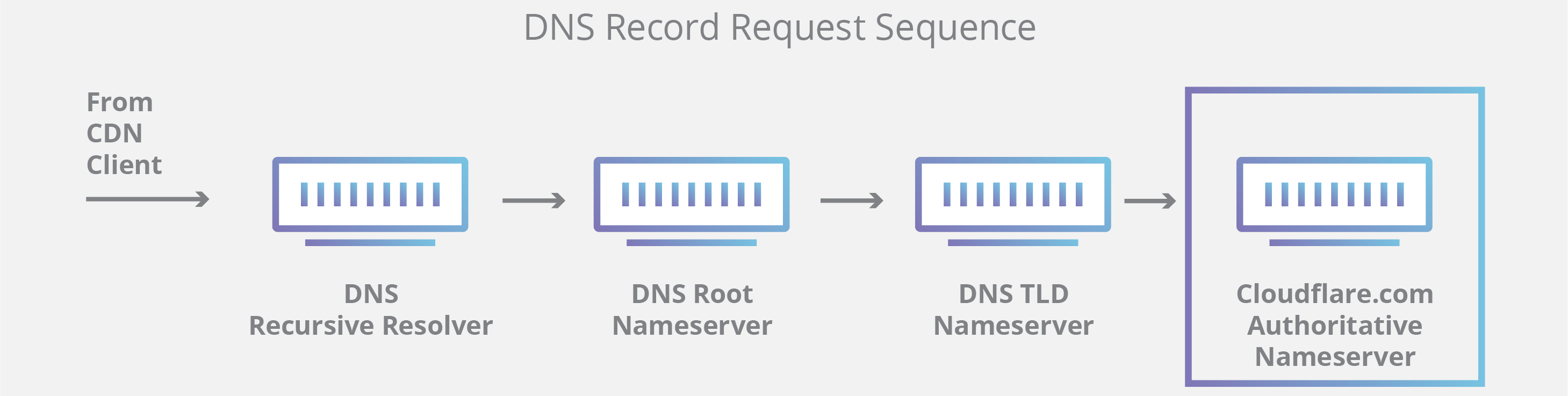
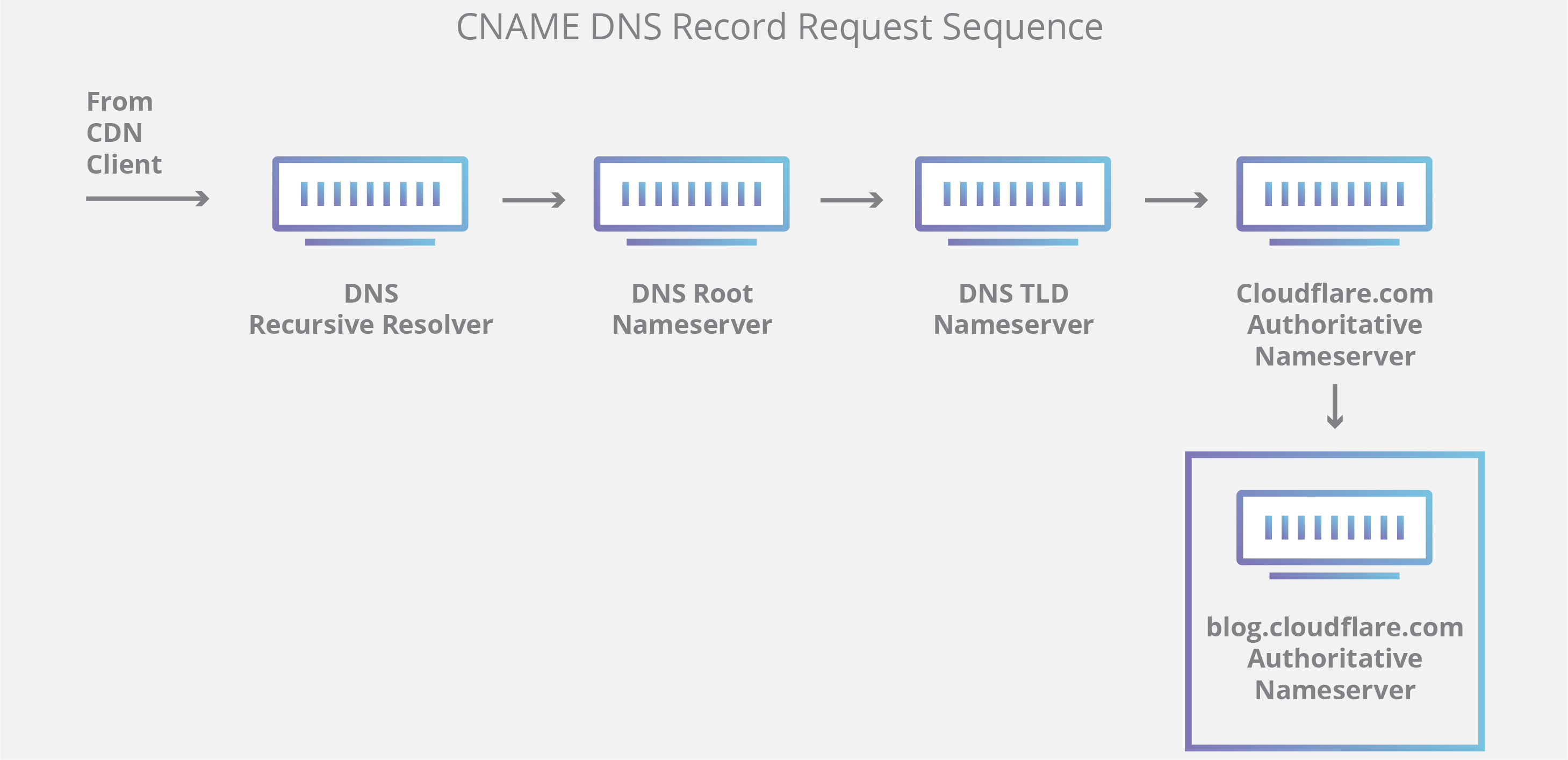
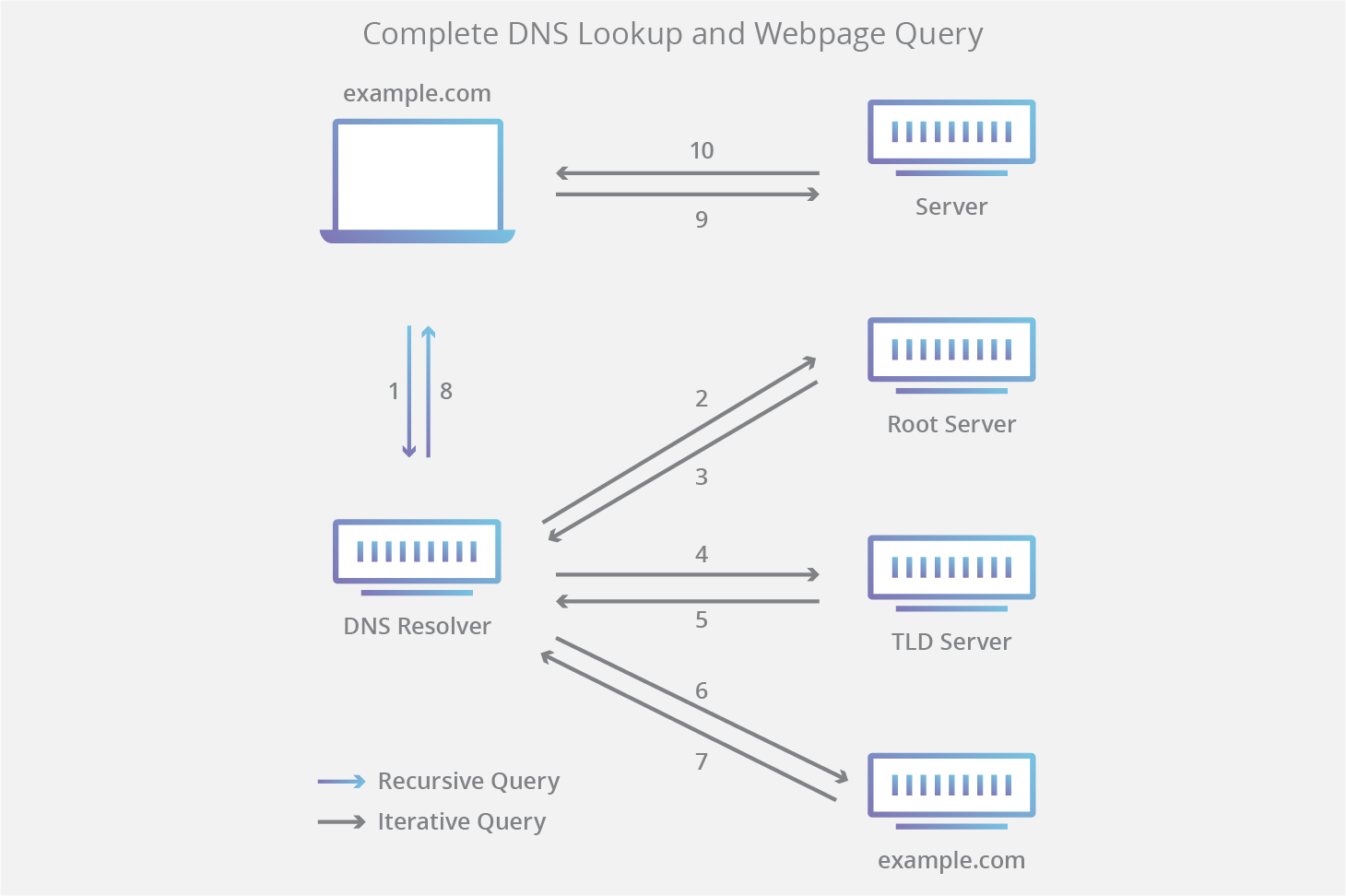
The Domain Name System (DNS) is the phonebook of the Internet. While humans access information online through domain names like example.com, computers do so using Internet Protocol (IP) addresses—unique strings of alphanumeric characters that are assigned to every Internet property. DNS translates domain names to IP addresses so users can access a website easily without having to know the site’s IP address.

What is a DNS resolver?
A DNS resolver is a type of server that manages the “name to address” translation, in which an IP address is matched to domain name and sent back to the computer that requested it. DNS resolvers are also known as recursive resolvers.
Computers are configured to talk to specific DNS resolvers, identified by IP address. Usually, the configuration is managed by the user’s Internet Service Provider (ISP) on home or wireless connections, and by a network administrator on office connections. Users can also manually change which DNS resolver their computers talk to.
Why use 1.1.1.1 instead of an ISP’s resolver?
The main reasons to switch to a third-party DNS resolver are to improve security and gain faster performance.
On the security side, ISPs do not always use strong encryption on their DNS or support the DNSSEC security protocol, making their DNS queries vulnerable to data breaches and exposing users to threats like on-path attacks. In addition, ISPs often use DNS records to track their users’ activity and behavior.
On the performance side, ISP’s DNS resolvers can be slow, and may become overloaded by heavy usage. If there is enough traffic on the network, an ISP’s resolver could stop answering requests altogether. In some cases, attackers deliberately overload an ISP’s recursors, resulting in a denial-of-service.
What makes 1.1.1.1 more secure than other public DNS services?
A variety of DNS services support DNSSEC. While this is a good security practice, it does not protect users’ queries from the DNS companies themselves. Many of these companies collect data from their DNS customers to use for commercial purposes, such as selling to advertisers.
By contrast, 1.1.1.1 does not mine user data. Logs are kept for 24 hours for debugging purposes, then they are purged.
1.1.1.1 also offers security features not available from many other public DNS services, such as query name minimization. Query name minimization improves privacy by only including in each query the minimum number of information required for that step in the resolution process.
What makes 1.1.1.1 the fastest recursive DNS service?
The power of the Cloudflare network gives 1.1.1.1 a natural advantage in terms of delivering speedy DNS queries. Since it is integrated into Cloudflare’s network, which spans 200 global cities, users anywhere in the world get a quick response from 1.1.1.1.
In addition, data centers in the network have access to the approximately 25 million Internet properties on the Cloudflare platform, making queries for those domains lightning-fast. Overall, the independent DNS monitor DNSPerf ranks 1.1.1.1 the fastest DNS service in the world:

What is Cloudflare WARP?
WARP is an optional app built on top of 1.1.1.1. WARP creates a secure connection between personal devices (like computers and smartphones) and the services you access on the Internet. While 1.1.1.1 only secures DNS queries, WARP secures all traffic coming from your device.
WARP does this by routing your traffic over the Cloudflare network rather than the public Internet. Cloudflare automatically encrypts all traffic, and is often able to accelerate it by routing it over Cloudflare’s low-latency paths. In this way, WARP offers some of the security benefits of a virtual public network (VPN) service, without the performance penalties and data privacy concerns that many for-profit VPNs bring.
How do I use 1.1.1.1 and WARP?
1.1.1.1 is completely free. Setting it up on a desktop computer takes minutes and requires no technical skill or special software. Users can simply open their computer’s Internet preferences and replace their existing DNS service’s IP address with the address 1.1.1.1. Instructions for different desktop operating systems are available here.
To use 1.1.1.1 or WARP on a phone, download the app, which is available here.